<property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> <description>Driver class name for a JDBC metastore</description> </property> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://192.168.231.1:3306/myhive</value> <description> JDBC connect string for a JDBC metastore. To use SSL to encrypt/authenticate the connection, provide database-specific SSL flag in the connection URL. For example, jdbc:postgresql://myhost/db?ssl=true for postgres database. </description> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> <description>Username to use against metastore database</description> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>root</value> <description>password to use against metastore database</description> </property> <property> <name>hive.metastore.ds.connection.url.hook</name> <value/> <description>Name of the hook to use for retrieving the JDO connection URL. If empty, the value in javax.jdo.option.ConnectionURL is used</description> </property> <property> <name>javax.jdo.option.Multithreaded</name> <value>true</value> <description>Set this to true if multiple threads access metastore through JDO concurrently.</description> </property>
Connection connection = DriverManager.getConnection("jdbc:hive2://192.168.231.100:10000/hive1", "ubuntu", "123456"); PreparedStatement preparedStatement = connection.prepareStatement("select * from t"); ResultSet rs = preparedStatement.executeQuery(); while (rs.next()) {
int id = rs.getInt("id"); String name = rs.getString("name"); int age = rs.getInt("age"); System.out.println(id + "," + name + "," + age); } rs.close(); preparedStatement.close(); connection.close();
}
6.常用聚集函数
count()
sum()
avg()
max()
min()
7.解决beeline命令行终端的上下键导航历史命令的bug
[bin/beeline]
修改行
if [[ ! $(ps -o stat= -p $$) =~ + ]]; then
为
if [[ ! $(ps -o stat- -p $$) =~ "+" ]]; then
hive命令
$hive>dfs -lsr / //执行dfs命令
$>hive>!clear; //执行shell脚本
$>hive -e "select * from test" //-e execute 一次性执行
$>hive -S -e "select * from test" //-S silent 静默,不输出OK,耗时
$>hive -f /path/x.hql //-f 执行一个文件,通常用于批处理
$hive>tab tab //显示所有命令
$hive>-- this is a comment //注释
$hive>set hive.cli.print.header=true; //现在字段名称(头)
$hive>create database if not exists xxx //
$hive>create database hive3 with dbproperties('author'='fth','createtime'='today') //
$hive>alter database hive3 set dbproperties('author'='fth_enchancer')
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
[创建表语法] CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.] table_name [(col_name data_type [COMMENT col_comment], ...)] [COMMENT table_comment] [ROW FORMAT row_format] [STORED AS file_format]
[例子] CREATE TABLE IF NOT EXISTS employee ( eid int, name String, salary String, destination String) COMMENT 'Employee details' //注释 ROW FORMAT DELIMITED //行格式定义 FIELDS TERMINATED BY '\t' //字段结束符 LINES TERMINATED BY '\n' //行结尾符 STORED AS TEXTFILE; //存储成何种文件
1 2 3 4 5 6 7
[加载数据 insert] load data local '/home/ubuntu/employee.txt' overwrite LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]
[例子] LOAD DATA LOCAL INPATH '/home/user/sample.txt' OVERWRITE INTO TABLE employee;
1 2 3 4 5 6 7 8 9 10
[创建分区表] create table test5(id int, name string, age int) partitioned by (province STRING,city STRING); //按照省份和城市分区
[例子] create table hive1.test5(id int,name string,age int) partitioned by(province string,city string) row format delimited fields terminated by '\t' lines terminated by '\n' stored as textfile;
1 2
[加载数据到指定分区] load data local inpath '/home/ubuntu/employees.txt' into table hive1.test5 partition(province='hebei',city='baoding');
[查看hdfs] /user/hive/warehouse/hive1.db/test5/province=hebei/city=baoding/employees.txt [查询分区表] $hive>select * from hive1.test5 where province = 'hebei' and city = 'baoding'; [分区表的查询模式:strict/nostrict] [严格/非严格] $hive>set hive.mapred.mode=strict || false?? //默认是非严格模式
[复制数据到分区表] $>insert into hive1.test5 partition (province='hebei',city='baoding') select * from hive1.test2; insert into hive1.test6 partition ( province='hebei',city='baoding') select id,name,age,birth,fire from hive1.test6 where province='hebei' and city='shijiazhuang' and id > 5 ; //字段个数相同,查询时,分区通过where子句制定,插入时,分区用partition(...)指定
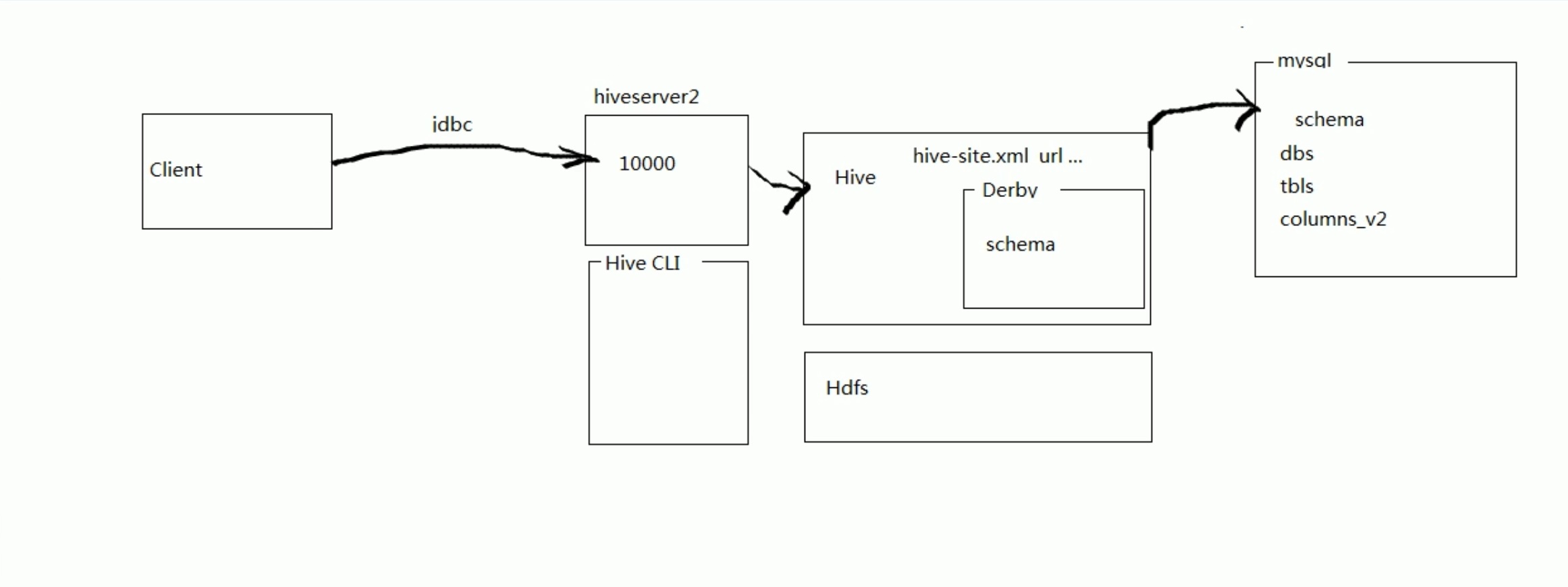


能否参与评论,且看个人手段。