面向内存的数据网格计算平台
why Ignite
1.Ignite是一个分布式的基于内存的数据库和缓存平台,可以用于事务分析和作为流式处理的计算平台,可提供PB级的内存速度
2.对数据的处理包括但不限于数据网格、计算网格、流计算,当然也包括数据结构。
3.提供了完整的SQL、DDL和DML的支持,可以使用纯SQL而不用写代码与Ignite进行交互,这意味着只使用SQL就可以创建表和索引,以及插入、更新和查询数据。有这个完整的SQL支持,Ignite就可以作为一种分布式SQL数据库。
目前的业务需要实时的对照人脸库进行人物移动轨迹的分析,需要在毫秒内处理上亿条的数据CRUD,目前的数仓,以及RDBMS是无法完成这项工作的
本文主要涉及使用Ignite来作为数据源的存储读取,以及在和springboot集成当中碰到的一些问题,使用的Ignite版本为2.7.6 。
与计算平台的集成(例如spark)参照官网
开始
下载
从我的部署安装过程来看Ignite是采用无主模式的,虽然这一点在官方文档中我并未找到明显的提示.
从配置文件属性看来,Ignite的应用模式分为客户端与服务器两种,如果未显示注明默认是服务器模式,进 行自动探测在同一个网络中的所有Ignite服务。这是部署在测试集群的配置(server模式)
- server和clinet模式最大区别就在于资源利用,client在未向server进行数据调用时是不占用资源的,而server对资源的占用是启动完以后就一直存在的(包括堆外内存的使用)
1 | <beans xmlns="http://www.springframework.org/schema/beans" |
替换配置$IGNITE_HOME/config/default-config.xml

- 要注意的是这里有个配置属性 consistentId 这是以后做分布式扩展时候要用到的,包括后面的持久化配置,先配上。
切换JDK1.8以上,强制的
启动
1 | ignite.sh |
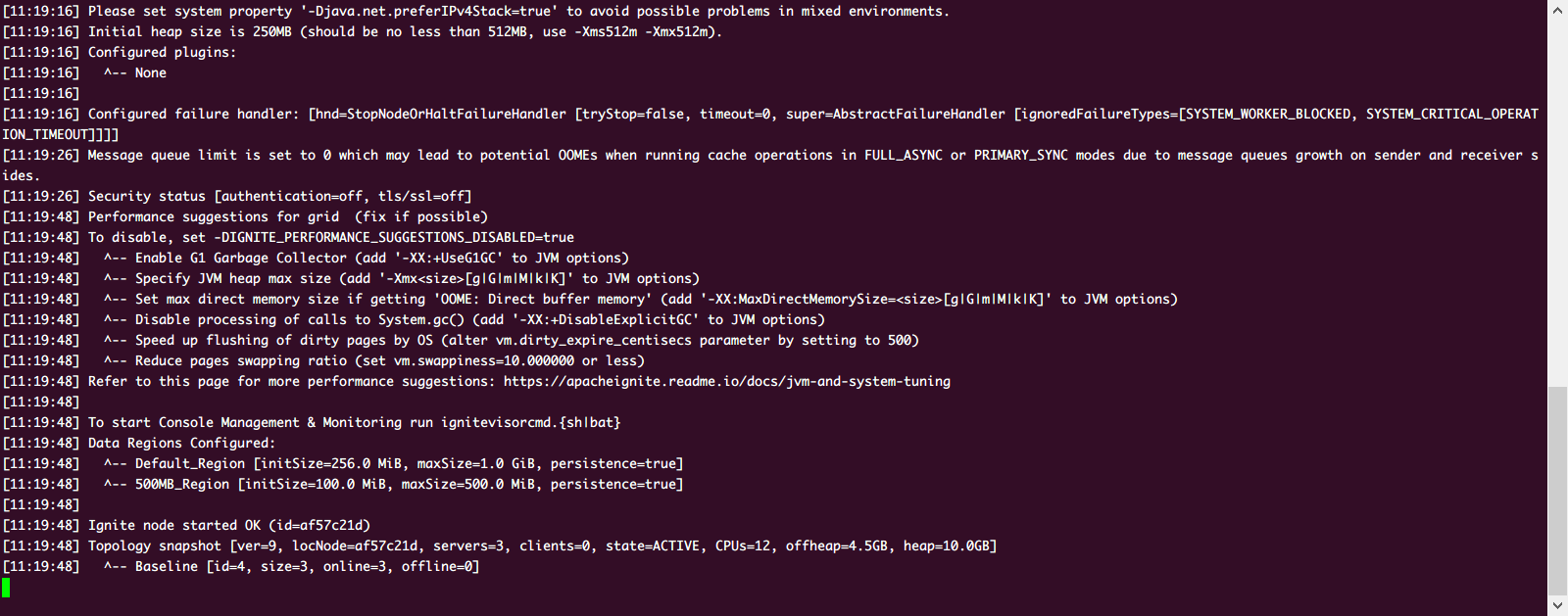
可以看到启动成功了,使用脚本看一下集群情况
1 | ./ignitevisorcmd.bat |
1 | open |

1 | top 查看集群情况 |
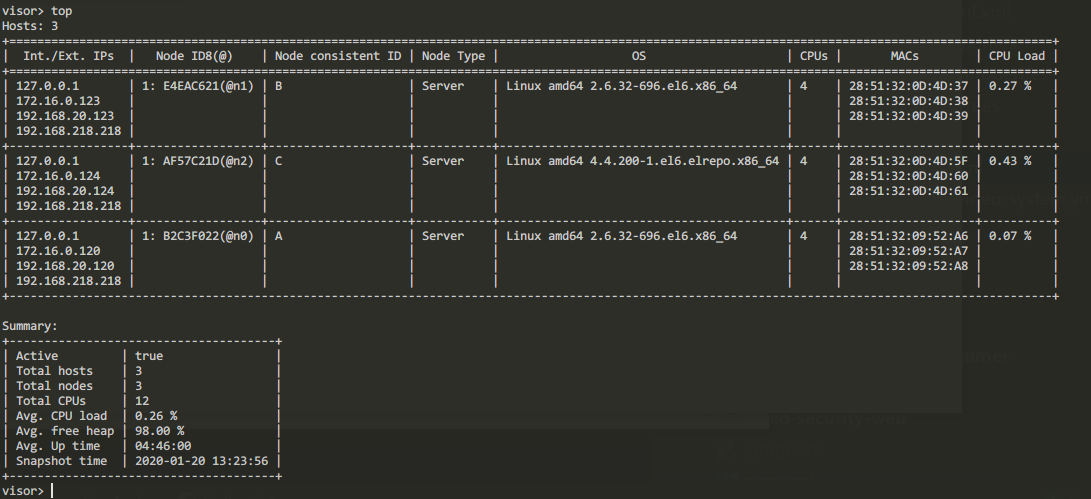
我同时部署了3个节点的服务器,作为和单节点部署区别是consistentId 不同。
所以可以基于这种嗅探模式很轻易的做到横向扩展。
可以看到已经自动探测到所有的节点信息,下面使用springboot集成ignite作为客户端进行cache的CRUD,这部分也是翻车频率最高的地方。
springboot版本 2.0.7.RELEASE
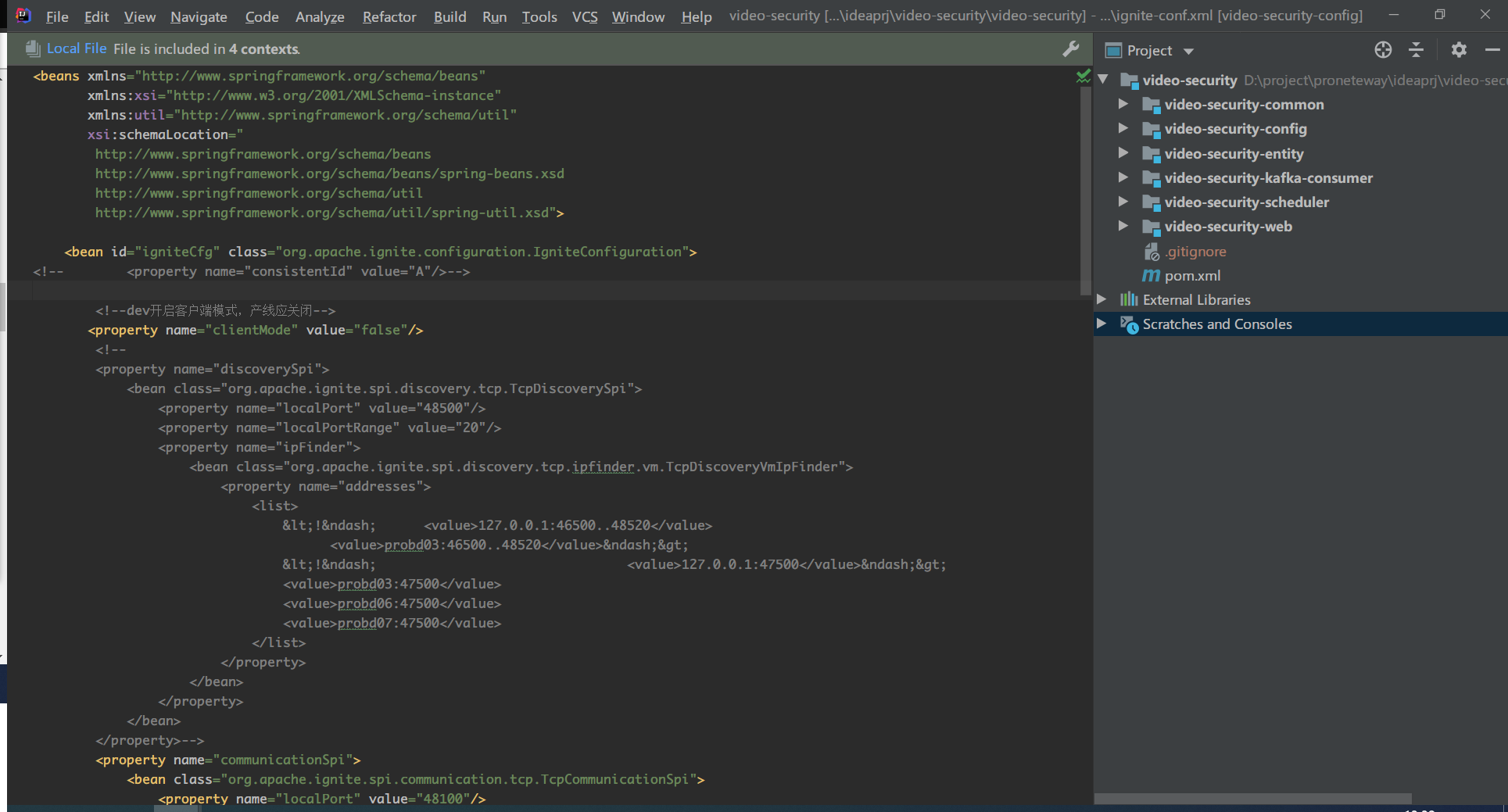
可以看到和服务端配置不同的地方是注明了clientMode 为false,这是在真正产线部署环境当中应该开启的模式。
现在换成true开启客户端模式做本地测试。
配置文件
1 | /** |
这份配置做了这几件事
- 读取xml配置文件中的属性,初始化IgniteConfiguration
- 新建了一个名为IgniteFaceCache的缓存
- 当集群模式刚启动之后,这个版本的ignite并不会自动切换至active,所以client连接到集群后将状态设置为active
main函数
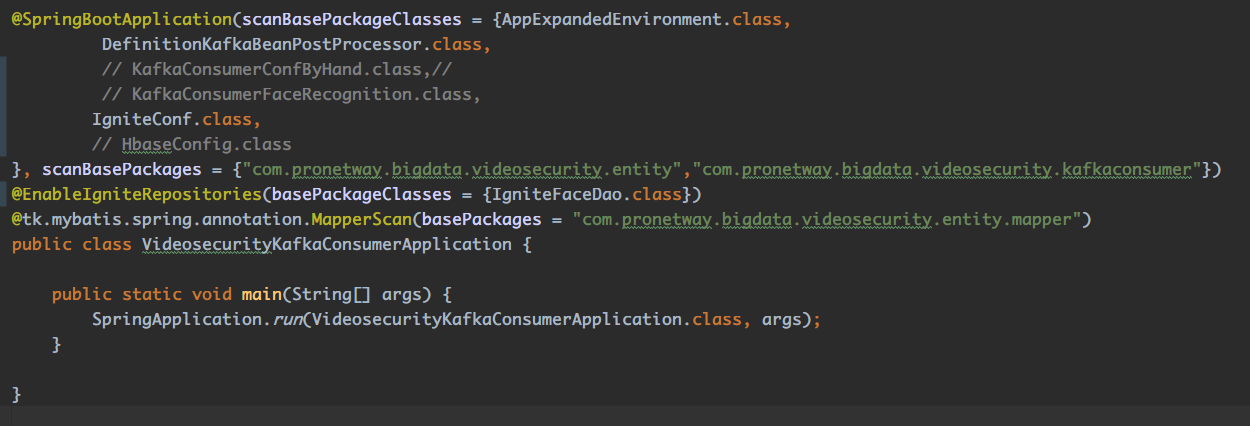
开启了@EnableIgniteRepositories 注解,使用JPA操纵cache
IgniteFaceDao
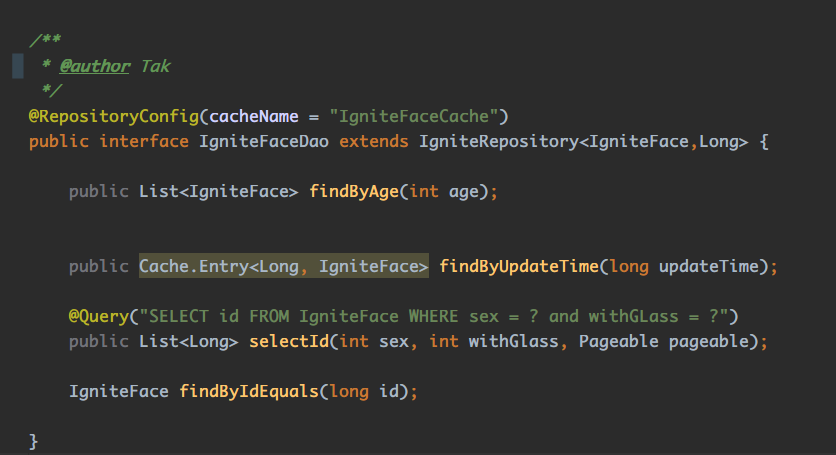
这里要注意引用ignite-spring-data是无法正常使用的,需要使用
1 | <dependency> |
否则会出现编译不通过的情况

编写测试程序,插入1亿条数据
1 | (classes = {DaoTests.class}) |
趁着导数据过程切换到visor窗口 输入node
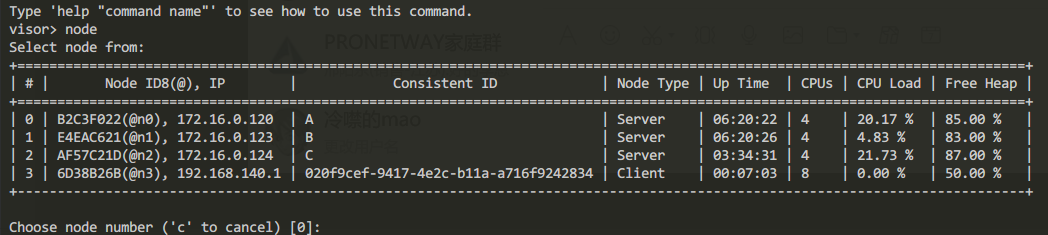
可以看到刚才本地启动的节点也已加入至集群(Client)
切换到visor窗口,输入cache
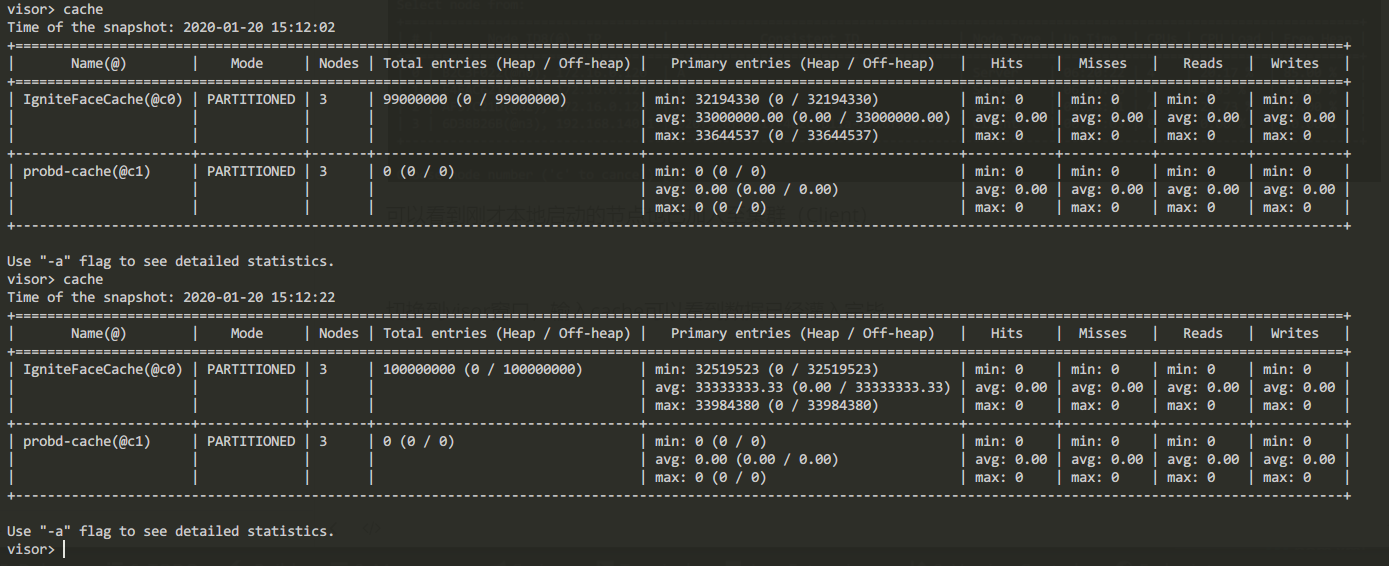
可以看到一亿条数据已经灌入完毕
编写controller查询数据
1 | /** |
测试请求
1 |
|
测试结果
1 | req id:17461275 |
- 第一次的查询偏慢,看看有没有后期调优的入口,其实从启动客户端的日志上就能看到,官方提供了参数调优指南
补上DTO的代码
1 | import org.apache.ignite.cache.affinity.AffinityKey; |
参考过的网站


能否参与评论,且看个人手段。