ES配置优化
优化目的
- 此次优化针对ES中fielddata无法正常GC造成资源紧张,无法接收DSL执行请求
常用配置
- 设置断路器,防止构建DSL超出集群资源极限
- 适当调大filedata上限阈值,加快搜索速度
1 | curl -XPUT 'localhost:9200/_cluster/settings' -d' |
- 预加载fielddata进入filesystemcache,即在建索引的时候就加载这样可以提升排序和统计的性能
1 | POST /test_index/_mapping/test_type |
- elasticsearch.yml: indices.fielddata.cache.size: 20%,超出限制,清除内存已有的fielddata。
也可以设置为绝对内存,比如16g
测试环境调优
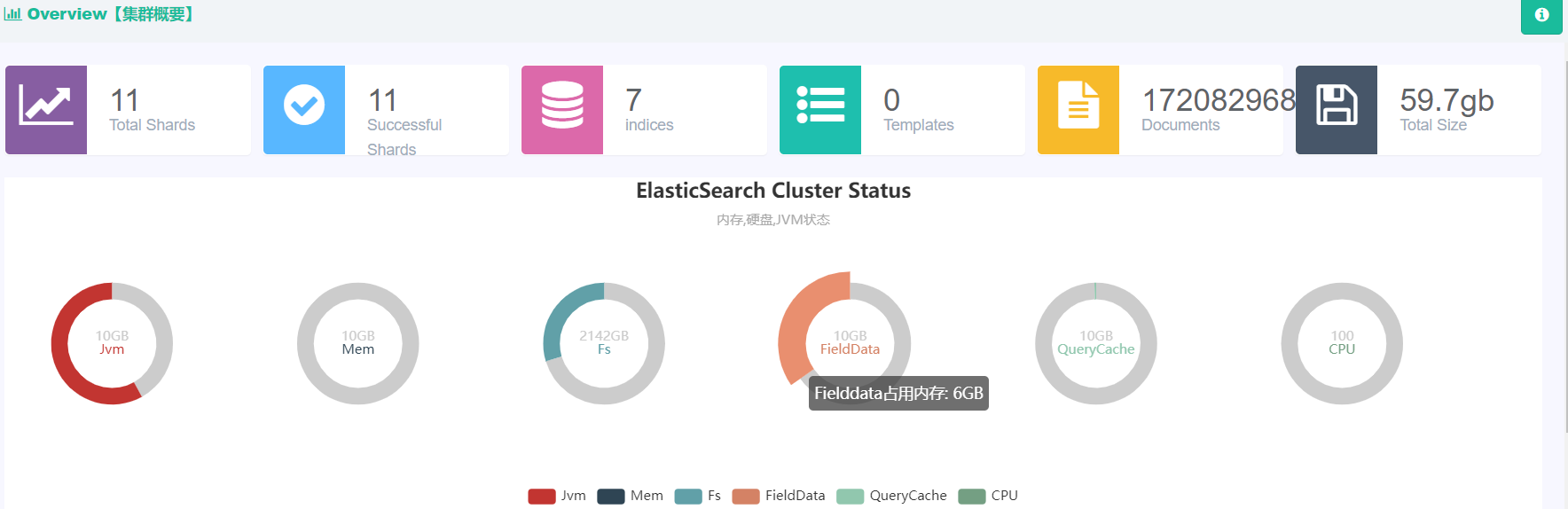
先看一下现有集群配置
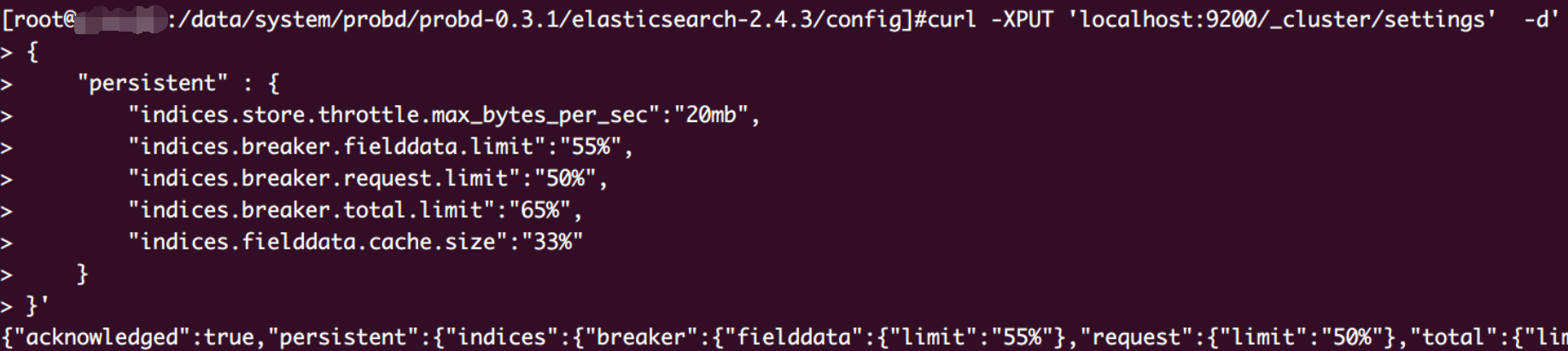
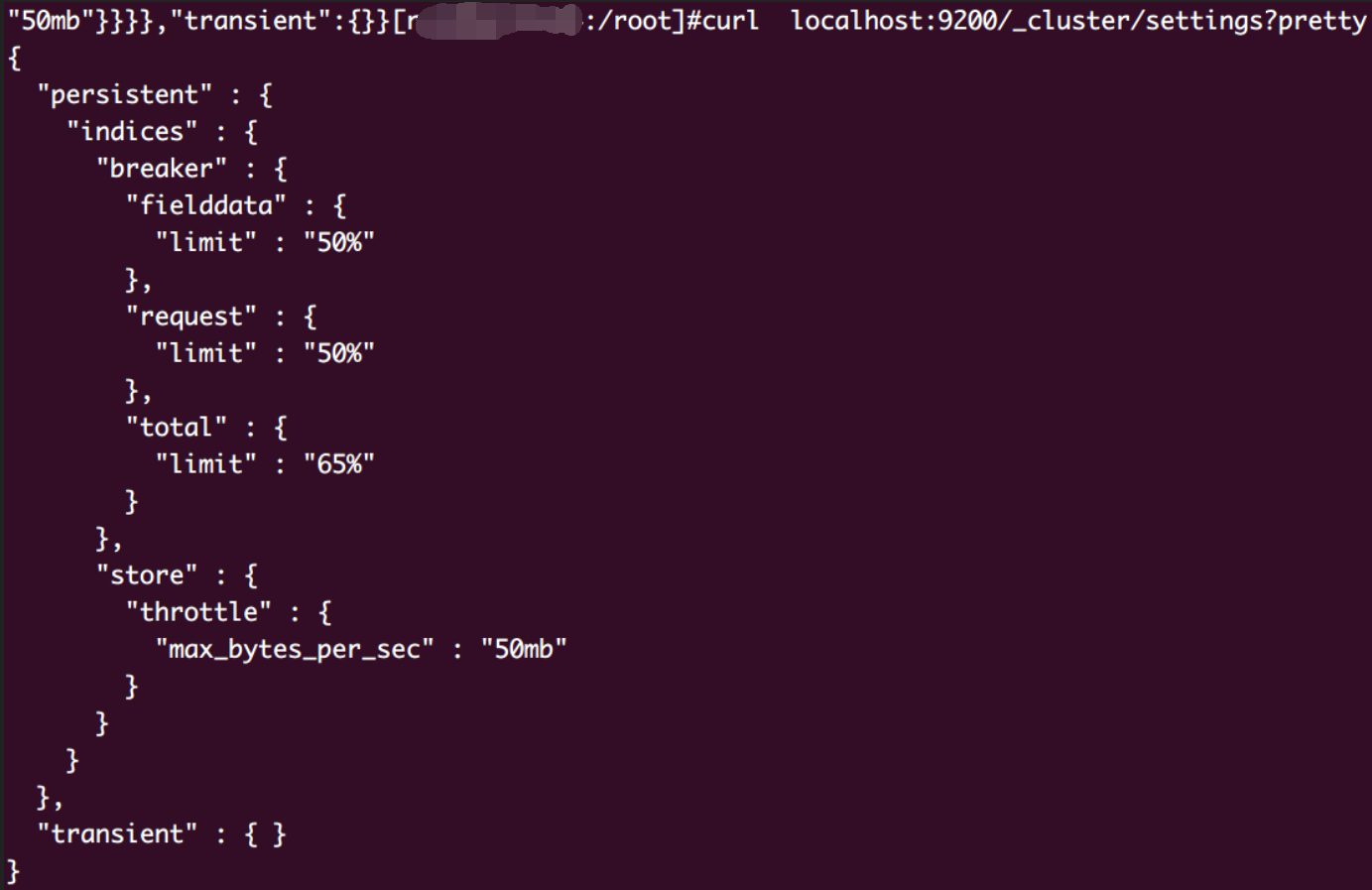
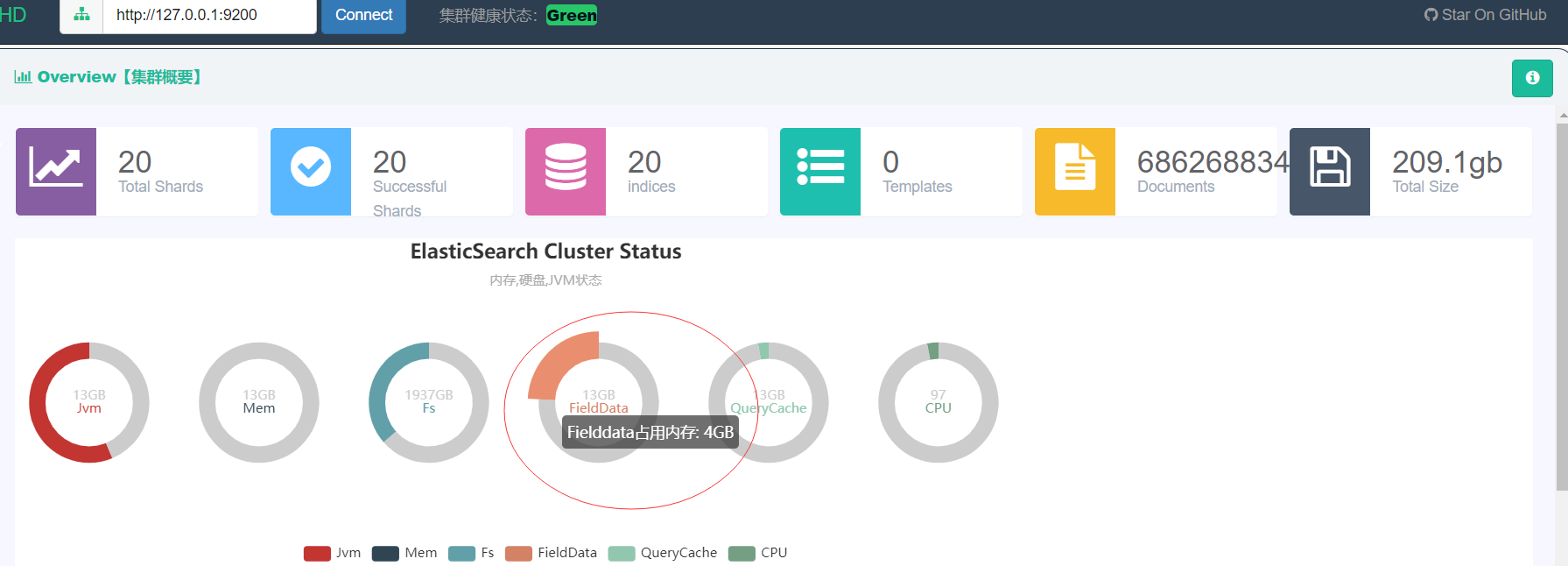
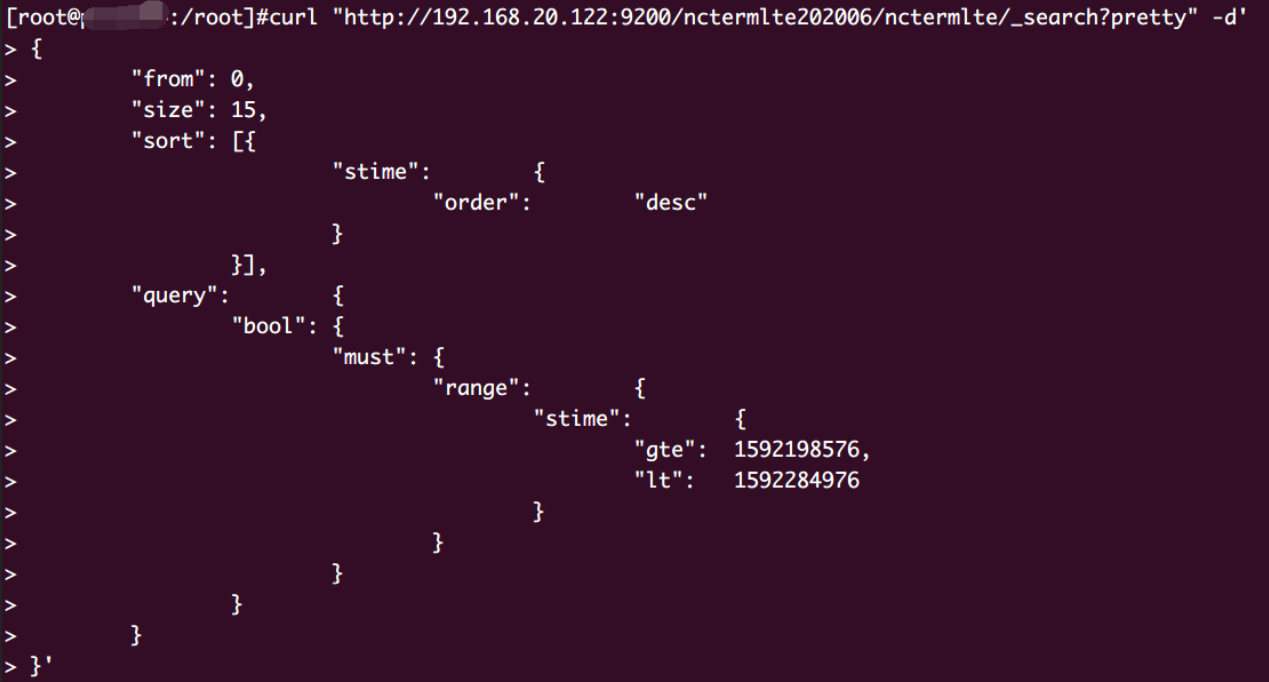
DSL请求
1 | 前端传来的测试语句 |
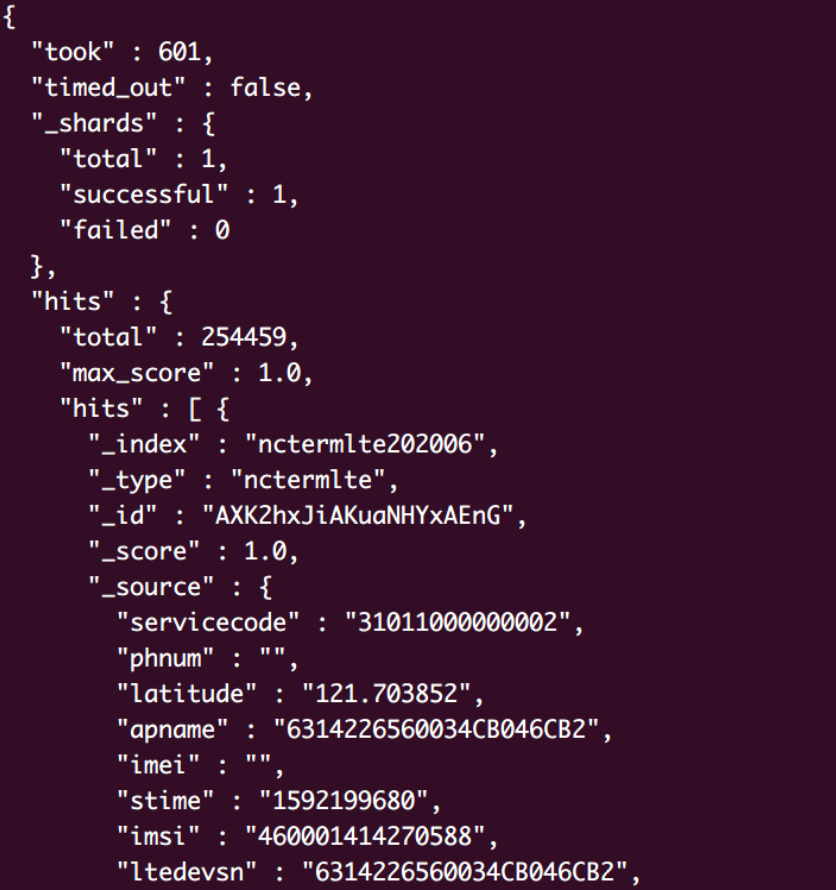
响应结果
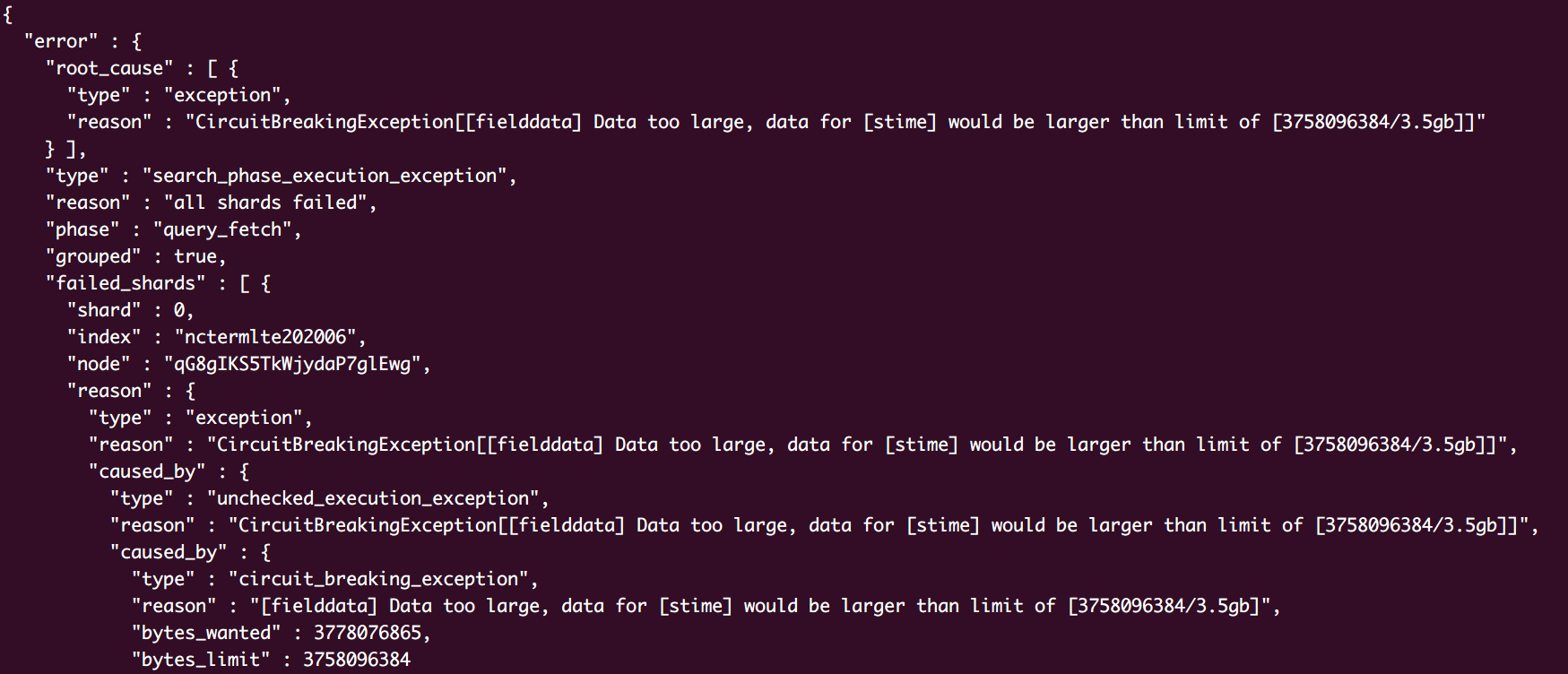
更换DSL语句响应结果
领导说此业务用了好几年了,完全没有这种问题,你们大数据这块肯定有问题,必须你们这里改,xxx.
开始调优

- fileddatacache
- 这个参数比率过小,导致无法充分利用集群的内存资源,大部分fielddata字段无法做到从filesystemcache中获取,需要调大
优化结束测试
完整配置
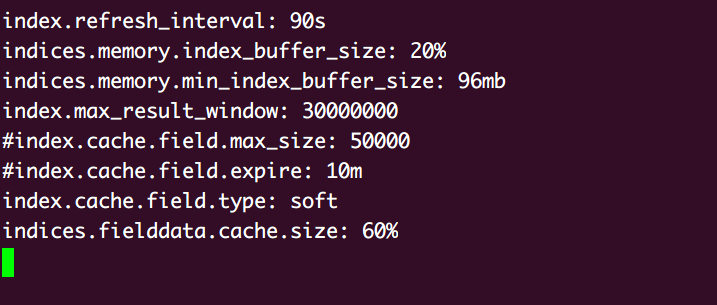
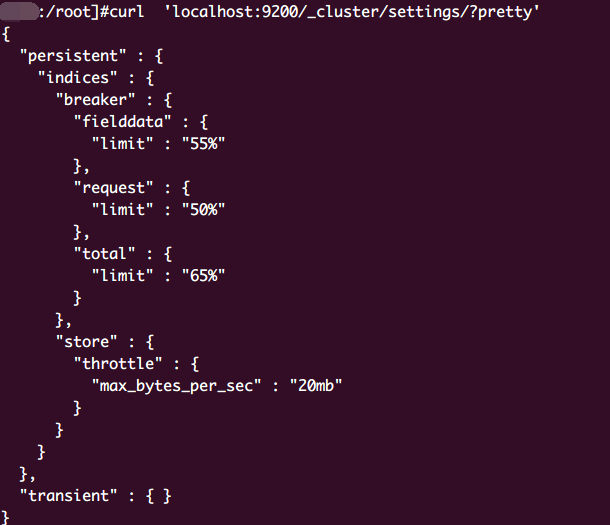
1 | cache设定值:产线等比率放大即可 |
fielddata相关查询命令
1 | GET /_stats/fielddata?fields=* //各个分片、索引的fielddata在内存中的占用情况 |
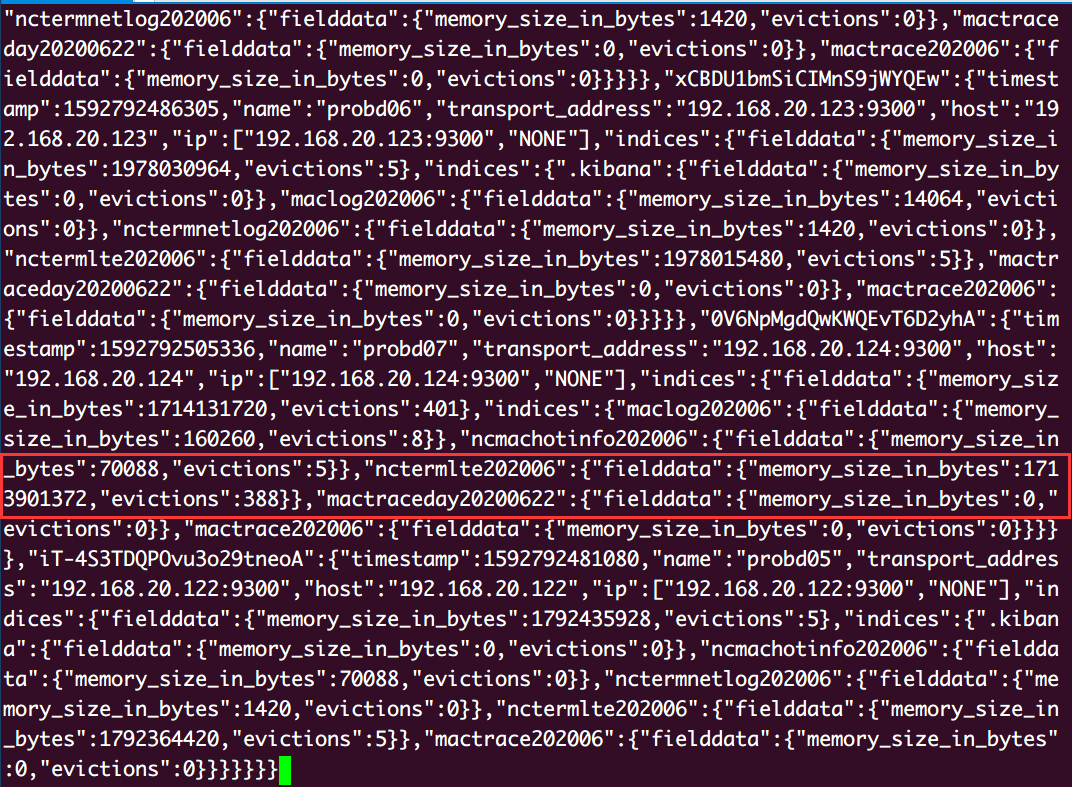
evictions次数的增加代表fileddata在达到设定的驱逐临界值(现有配置50%)
后被执行了GC清除
总结
fileddata正在按照设定的上限阈值被gc,而这个上限值在ES默认配置当中是无限大
如果不手动设定这个上线阈值,会造成fileddata从不被GC(驱逐)
通过以上配置 (fielddata使用上限百分比(值),驱逐百分比(值) ) 并且配合断路器
可以做到有效安全的利用fileddata,快速查询document!
参考
一些配置参数
1 | # 使用bulkAPI档次最大接收数据的大小,首次可以适当放大,根据每次增加插入大小来观察文档入库的效率,直到速度不再增加以后将这个值设为最大值 |


能否参与评论,且看个人手段。