clickhouse与ES在千万级结果集输出场景下的性能分析
感谢我的同事参与这次的新型数据库探索,合作完成这份性能分析.
docker启动
1 | docker run -d --name some-clickhouse-server --ulimit nofile=262144:262144 -v /path/to/your/config.xml:/etc/clickhouse-server/config.xml yandex/clickhouse-server |
Clickhouse与Elasticsreach的优缺点
clickhouse
- 优点
- 支持标准SQL语法
- 支持多核多节点并行化大型查询。
- 高性能的OLAP查询引擎,是目前单表查询最快的
- 支持HTTP访问数据,可在浏览器直接查询数据库数据
- 缺点
- 没有完整的事务支持
- 缺少高频率,低延迟的修改或删除已存在数据的能力,仅能用于批量删除或修改数据
elasticsreach
- 优点
- 高效的搜索框架,搜索和全文检索性能很好
- 缺点
- 查询结果集太大,取全量数据会造成深度分页,性能很差
- 使用领域特定语言(DSL),学习成本更高
Clickhouse与Elasticsreach查询数据性能对比
测试环境,测试资源基础信息
集群为测试集群
Clickhouse为单节点
Elasticsearch 4节点集群,总资源情况内存28个G
Elasticsearch测试集群详细资源分布参考以下连接
Clickhouse单机启动占用100MB资源
测试情况
| 单表数据量 | 查询返回的结果集 | 花费时间 | |
|---|---|---|---|
| Clickhouse | 7亿6千万 | 36900409(3690万) | 1.6(分钟) |
| elasticsreach | 172920564 | 3960027(396万) | 8(分钟) |
在clickhouse表数据比es大4.4倍,返回结果集比es大9.3倍,花费时间只有es的1/5
对比过程截图
Clickhouse
在clickhouse中,nctermlte表存在7亿6千万条数据
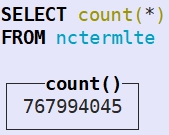
我们对该表做范围查找,结果集为3690万条,拉取到内存,花费时间1.6分钟

Elasticsreach
在Elasticsreach中,nctermlte202006表存在一亿七千万条数据
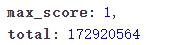
我们对该表做同样的范围查找,结果集为396万条数据,花费时间8分钟

测试结果:
资源情况:ES节点4个,Clickhouse单节点.
相同结果数据量拉取对比:Clickhouse比Elasticsearch快了50倍
对比总结
Elasticsearch
默认参数设置过于繁琐,出厂默认甚至不限制最大filesystemcache的使用值
如果不采取优化DSL,或者不进行断路器设置(这些都需要额外配置)会造成集群不健康,吞吐量下降,甚至致使集群不工作,无法使用,直到人为干预。
检索数据量一旦超过百万级,明显无法满足我们的数据分析实时性
不支持复杂查询,连表查询
无法做到检索逻辑完全下推
Clickhouse
- 部署简单,不需要过多的参数设置,不需要对内存清理进行干预(c++编写)
- 初始化资源要求低,100MB内存即可,不处理查询时会自动释放大部分内存
- 通过http,可以使用sql语句直接查询数据,当然特定编程语言指定依赖驱动也可以通过tcp连接
- 支持通用SQL语法,可以做到连表查询,子查询,甚至自定义的窗口函数,视图
- 可以将检索逻辑完全下推到数据库引擎中
我为什么支持使用Clickhouse
适合大数据分析场景,不需要修改删除,我只需要快速的拉取数据然后并行分析数据
支持通用SQL语法,支持完整的谓词下推,可以花费极少的学习代价,做到精准过滤想要的数据
ES的调优集群维护过于复杂,官方文档老旧(只针对2.0编写),现有场所集群版本老旧,因为Lucene版本不一致,法做到滚动更新ES版本
IPC调用简单,例如使用

真正做到跨语言,标准sql查询逻辑
可以使用类似mysql 通过terminal连接做即席查询
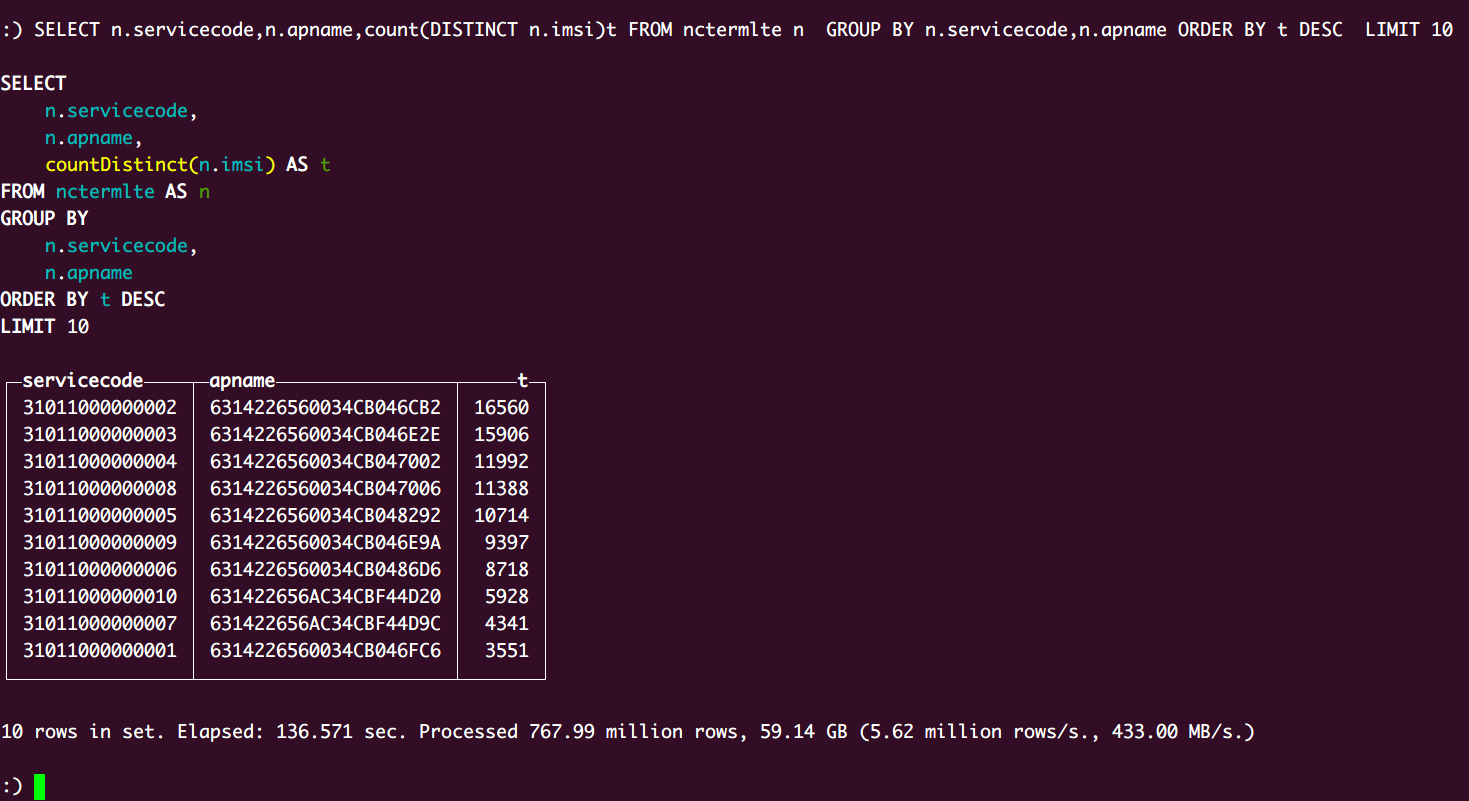
各场所Imsi采集数TOP 10


能否参与评论,且看个人手段。