Yarn、 容量调度、 HDFS、Spark
测试集群
测试集群为Standalone模式
hdfs-site.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
<configuration>
<!-- About service -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>probd04:50090</value>
</property>
<property>
<name>dfs.namenode.secondary.https-address</name>
<value>probd04:50091</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>
file:///data/system/probd/probd-0.3.1/hadoop-2.6.3/name
</value>
</property>
<!-- About datanode -->
<property>
<name>dfs.datanode.data.dir</name>
<value>
file:///data/system/probd/probd-0.3.1/hadoop-2.6.3/data/dfs/data
</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- About web hdfs -->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
yarn-site.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
<configuration>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>10240</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle,spark_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>probd02:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>probd02:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>probd02:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>probd02:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>probd02:8088</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>32</value>
</property>
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
<description>
Whether physical memory limits will be enforced for containers.
</description>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
<description>
Whether virtual memory limits will be enforced for containers.
</description>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>10240</value>
</property>
<property>
<name>yarn.app.mapreduce.am.resource.mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.app.mapreduce.am.command-opts</name>
<value>-Xmx1024m</value>
</property>
<property>
<name>spark.shuffle.service.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.spark_shuffle.class</name>
<value>org.apache.spark.network.yarn.YarnShuffleService</value>
</property>
<property>
<name>spark.shuffle.service.port</name>
<value>7337</value>
</property>
<!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!-- 日志聚集功能使能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 日志保留时间设置7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<!--<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
</property>-->
<property>
<name>yarn.scheduler.minimum-allocation-vcores</name>
<value>20</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-vcores</name>
<value>32/value>
</property>
</configuration>
capacity-scheduler
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26<configuration>
<property>
<name>yarn.scheduler.capacity.root.queues</name>
<value>default</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.capacity</name>
<value>100</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.maximum-capacity</name>
<value>100</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.user-limit-factor</name>
<value>1</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.acl_submit_applications</name>
<value>*</value>
</property>
<property>
<name>yarn.scheduler.capacity.resource-calculator</name>
<value>org.apache.hadoop.yarn.util.resource.DominantResourceCalculator</value>
</property>
</configuration>mapred-site.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>probd03:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>probd03:19888</value>
</property>
</configuration>
产线
硬件
内存
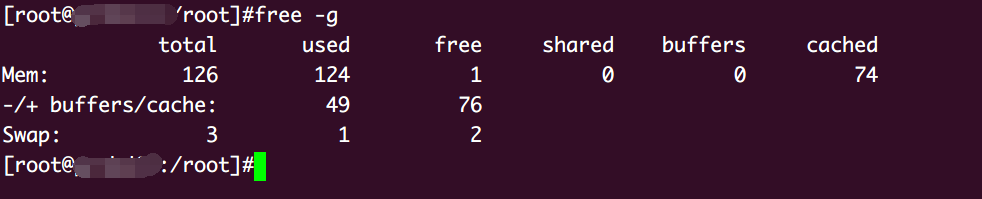
核心

配置
yarn-site.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
<configuration>
<!-- resourcemanager -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yarn-probd</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>probd02</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>probd03</value>
</property>
<!-- About zookeeper -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>probd02:2181,probd03:2181,probd04:2181</value>
</property>
<!-- About nodemanager memory allocate, that is, NM memory resource -->
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>40960</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>40960</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>8032</value>
</property>
<!-- About nodemanager CPU allocate, that is, NM CPU resource -->
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>40</value>
<description>
Number of vcores that can be allocated for containers.
This is used by the RM scheduler when allocating resources for containers.
This is not used to limit the number of physical cores used by YARN containers.
</description>
</property>
<property>
<name>yarn.nodemanager.resource.percentage-physical-cpu-limit</name>
<value>100</value>
<description>
Percentage of CPU that can be allocated for containers.
This setting allows users to limit the amount of CPU that YARN containers use.
Currently functional only on Linux using cgroups.
The default is to use 100% of CPU.
</description>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://probd:19888/jobhistory/job/</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>864000</value>
</property>
<property>
<name>spark.shuffle.service.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.spark_shuffle.class</name>
<value>org.apache.spark.network.yarn.YarnShuffleService</value>
</property>
<property>
<name>spark.shuffle.service.port</name>
<value>7337</value>
</property>
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
</configuration>hdfs-site.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<!-- About service -->
<property>
<name>dfs.nameservices</name>
<value>probd</value>
<description>For all clusters.</description>
</property>
<!-- About namenode -->
<property>
<name>dfs.ha.namenodes.probd</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.probd.nn1</name>
<value>probd02:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.probd.nn2</name>
<value>probd03:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.probd.nn1</name>
<value>probd02:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.probd.nn2</name>
<value>probd03:50070</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>
file:///probd/probd-0.3.1/hadoop-2.6.3/name
</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://probd02:8485;probd03:8485;probd04:8485/probd</value>
</property>
<!-- About journal node -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/probd/probd-0.3.1/hadoop-2.6.3/qjm</value>
</property>
<!-- About sshfence -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>shell(/bin/true)</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!-- About datanode -->
<property>
<name>dfs.datanode.data.dir</name>
<value>
file:///probd/probd-0.3.1/hadoop-2.6.3/data/dfs/data
</value>
</property>
<property>
<name>dfs.datanode.handler.count</name>
<value>30</value>
<description>thread count for request</description>
</property>
<property>
<name>dfs.datanode.max.xcievers</name>
<value>4096</value>
</property>
<property>
<name>dfs.datanode.du.reserved</name>
<value>10737418240</value>
<description>10G</description>
</property>
<property>
<name>dfs.datanode.directoryscan.threads</name>
<value>3</value>
<description>
How many threads should the threadpool used to compile reports
for volumes in parallel have.
</description>
</property>
<!--
<property>
<name>dfs.datanode.ipc.address</name>
<value>node102.probd:50020</value>
</property>
<property>
<name>dfs.datanode.http.address</name>
<value>node102.probd:50075</value>
</property>
-->
<!-- About client failover -->
<property>
<name>dfs.client.failover.proxy.provider.probd</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- About failover -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- About replication -->
<!--
<property>
<name>dfs.replication.max</name>
<value>3</value>
</property>
-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--
<property>
<name>dfs.datanode.ipc.address</name>
<value>node102.probd:50020</value>
</property>
<property>
<name>dfs.datanode.http.address</name>
<value>node102.probd:50075</value>
</property>
-->
<!-- About web hdfs -->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<!-- About dfsadmin -->
<property>
<name>dfs.hosts.exclude</name>
<value>/probd/probd-0.3.1/hadoop-2.6.3/etc/hadoop/nodes-exclude</value>
</property>
<!-- About balance -->
<property>
<name>dfs.balance.bandwidthPerSec</name>
<value>10485760</value>
<description>
Specifies the maximum bandwidth that each datanode can utilize
for the balancing purpose in term of the number of bytes per second.
the current value is 10M/S,default is 1M/S
</description>
</property>
<!-- add: 1 namenode:time out-->
<property>
<name>dfs.qjournal.write-txns.timeout.ms</name>
<value>90000</value>
</property>
<property>
<name>dfs.qjournal.start-segment.timeout.ms</name>
<value>120000</value>
</property>
<property>
<name>dfs.qjournal.select-input-streams.timeout.ms</name>
<value>120000</value>
</property>
<property>
<name>ha.zookeeper.session-timeout.ms</name>
<value>120000</value>
</property>
<property>
<name>dfs.qjournal.prepare-recovery.timeout.ms</name>
<value>600000000</value>
</property>
<property>
<name>dfs.qjournal.accept-recovery.timeout.ms</name>
<value>600000000</value>
</property>
<property>
<name>dfs.qjournal.finalize-segment.timeout.ms</name>
<value>600000000</value>
</property>
<property>
<name>dfs.qjournal.get-journal-state.timeout.ms</name>
<value>600000000</value>
</property>
<property>
<name>dfs.qjournal.new-epoch.timeout.ms</name>
<value>600000000</value>
</property>
<property>
<name>dfs.image.transfer.bandwidthPerSec</name>
<value>1048576</value>
</property>
<property>
<name>dfs.namenode.handler.count</name>
<value>30</value>
<description>thread count for request</description>
</property>
<property>
<name>dfs.datanode.socket.write.timeout</name>
<value>10800000</value>
</property>
<property>
<name>dfs.client.socket-timeout</name>
<value>600000</value>
</property>
<!--
<property>
<name>dfs.datanode.fsdataset.volume.choosing.policy</name>
<value>org.apache.hadoop.hdfs.server.datanode.fsdataset.AvailableSpaceVolumeChoosingPolicy</value>
</property>
<property>
<name>dfs.datanode.available-space-volume-choosing-policy.balanced-space-threshold</name>
<value>32212254720</value>
</property>
<property>
<name>dfs.datanode.available-space-volume-choosing-policy.balanced-space-preference-fraction</name>
<value>1</value>
</property> -->
</configuration>capacity-scheduler.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<configuration>
<property>
<name>yarn.scheduler.capacity.maximum-applications</name>
<value>10000</value>
<description>
Maximum number of applications that can be pending and running.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.maximum-am-resource-percent</name>
<value>0.1</value>
<description>
Maximum percent of resources in the cluster which can be used to run
application masters i.e. controls number of concurrent running
applications.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.resource-calculator</name>
<value>org.apache.hadoop.yarn.util.resource.DefaultResourceCalculator</value>
<description>
The ResourceCalculator implementation to be used to compare
Resources in the scheduler.
The default i.e. DefaultResourceCalculator only uses Memory while
DominantResourceCalculator uses dominant-resource to compare
multi-dimensional resources such as Memory, CPU etc.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.queues</name>
<value>default</value>
<description>
The queues at the this level (root is the root queue).
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.capacity</name>
<value>100</value>
<description>Default queue target capacity.</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.user-limit-factor</name>
<value>1</value>
<description>
Default queue user limit a percentage from 0.0 to 1.0.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.maximum-capacity</name>
<value>100</value>
<description>
The maximum capacity of the default queue.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.state</name>
<value>RUNNING</value>
<description>
The state of the default queue. State can be one of RUNNING or STOPPED.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.acl_submit_applications</name>
<value>*</value>
<description>
The ACL of who can submit jobs to the default queue.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.acl_administer_queue</name>
<value>*</value>
<description>
The ACL of who can administer jobs on the default queue.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.node-locality-delay</name>
<value>40</value>
<description>
Number of missed scheduling opportunities after which the CapacityScheduler
attempts to schedule rack-local containers.
Typically this should be set to number of nodes in the cluster, By default is setting
approximately number of nodes in one rack which is 40.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.queue-mappings</name>
<value></value>
<description>
A list of mappings that will be used to assign jobs to queues
The syntax for this list is [u|g]:[name]:[queue_name][,next mapping]*
Typically this list will be used to map users to queues,
for example, u:%user:%user maps all users to queues with the same name
as the user.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.queue-mappings-override.enable</name>
<value>false</value>
<description>
If a queue mapping is present, will it override the value specified
by the user? This can be used by administrators to place jobs in queues
that are different than the one specified by the user.
The default is false.
</description>
</property>
</configuration>mapred-site.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapred.output.compress</name>
<value>true</value>
<description>
Should the job outputs be compressed?
</description>
</property>
<property>
<name>mapred.output.compression.type</name>
<value>RECORD</value>
<description>
If the job outputs are to compressed as SequenceFiles, how should
they be compressed? Should be one of NONE, RECORD or BLOCK.
</description>
</property>
<property>
<name>mapred.output.compression.codec</name>
<value>org.apache.hadoop.io.compress.SnappyCodec</value>
<description>
If the job outputs are compressed, how should they be compressed?
</description>
</property>
<property>
<name>mapred.compress.map.output</name>
<value>true</value>
<description>
Should the outputs of the maps be compressed before being
sent across the network. Uses SequenceFile compression.
</description>
</property>
<property>
<name>mapred.map.output.compression.codec</name>
<value>org.apache.hadoop.io.compress.SnappyCodec</value>
<description>
If the map outputs are compressed, how should they be compressed?
</description>
</property>
<!--
<property>
<name>mapreduce.job.ubertask.enable</name>
<value>true</value>
</property>
<property>
<name>mapreduce.job.ubertask.maxmaps</name>
<value>9</value>
</property>
<property>
<name>mapreduce.job.ubertask.maxreduces</name>
<value>1</value>
</property>
-->
<!-- About memory resource allocate -->
<property>
<name>mapreduce.map.memory.mb</name>
<value>20480</value>
<description>
The amount of memory to request from the scheduler for each map task.
</description>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>20480</value>
<description>
The amount of memory to request from the scheduler for each reduce task.
</description>
</property>
<property>
<name>mapreduce.child.java.opts</name>
<value>-Xmx10240m</value>
</property>
<!--
<property>
<name>mapreduce.map.java.opts</name>
<value>-Xmx800m</value>
</property>
<property>
<name>mapreduce.reduce.java.opts</name>
<value>-Xmx800m</value>
</property>
-->
<!-- About memory resource allocate -->
<property>
<name>mapreduce.map.cpu.vcores</name>
<value>20</value>
<description>
The number of virtual cores to request from the scheduler for each map task.
</description>
</property>
<property>
<name>mapreduce.reduce.cpu.vcores</name>
<value>20</value>
<description>
The number of virtual cores to request from the scheduler for each reduce task.
</description>
</property>
</configuration>
说明
应用为基于webservice接收请求包装分析任务处理的web应用,sparkContext生命周期是和web程序挂钩的
所以容量调度只有一个队列,并且初始化占满所有资源.
spark(测试集群和产线同)
spark-env.sh
1
2
3
4
5
6
7
8
9
10
11
12export SPARK_HOME=/probd/probd-0.3.1/spark-2.2.3-bin-hadoop-2.6
export HADOOP_HOME=/probd/probd-0.3.1/hadoop-2.6.3
export YARN_HOME=/probd/probd-0.3.1/hadoop-2.6.3
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export YARN_CONF_DIR=${YARN_HOME}/etc/hadoop
export SPARK_YARN_USER_ENV="CLASSPATH=${HADOOP_HOME}/etc/hadoop"
export LD_LIBRARY_PATH=${HADOOP_HOME}/lib/native
export SCALA_HOME=/usr/lib/scala-2.11.8
export JAVA_HOME=/usr/lib/java/jdk1.8.0_171
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=probd02:2181,probd03:2181,probd04:2181 -Dspark.deploy.zookeeper.dir=/spark223 -Dspark.storage.blockManagerHeartBeatMs=6000000 -Dspark.rpc.askTimeout=300 -Dspark.ui.retainedStages=1000 -Dspark.worker.timeout=300"
SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://probd/spark223/job/history"
YARN_CONF_DIR=${HADOOP_HOME}/etc/hadoopspark-default.conf
1
2
3
4
5
6
7
8-XX:MetaspaceSize=2G -XX:MaxMetaspaceSize=2G
2048 #不建议使用,unsafeWriter并不稳定
5G
true
hdfs://probd/spark223/job/history
http://probd02:18080
=64m #不建议使用,unsafeWriter并不稳定
=64k #不建议使用,unsafeWriter并不稳定spark-sbumit 完整脚本重定向到github
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19nohup $SPARK_HOME/bin/spark-submit \
--master yarn \
--deploy-mode client \
--name onlineAnalyse \
--num-executors ${en} \
--driver-memory 3g \
--driver-cores 2 \
--executor-memory 35g \
--executor-cores ${ec} \
--driver-java-options "-Dlog4j.configuration=file:${prop} \
-Dexecutor.num=${en} -Dexecutor.core=${ec} \
-XX:+PrintGCApplicationConcurrentTime -Xloggc:gc.log" \
--conf spark.driver.port=20002 \
--conf spark.default.parallelism=300 \
--conf spark.driver.maxResultSize=2g \
--conf spark.kryoserializer.buffer.max=256m \
--conf spark.kryoserializer.buffer=128m \
--conf spark.memory.fraction=0.8 \
{ANY}.jar 2>&1 &


能否参与评论,且看个人手段。